Intro to Data Science : Lesson 3
Intro to Data Science Online Course - Udacity
Lesson 3: Data Analysis
- 問題形式
- 正しい記述を選択する
- Statistical Rigor
- rigor 〔基準などの〕厳しさ、厳密さ
- Significance tests
- significance 《統計》有意性
- Scientist at Twitter (4, 5番目の動画インタビュー)
- overinterpret ~を拡大解釈する[過剰に解釈する・深読みし過ぎる]
- Probability distribution
- Normal Distribution 正規分布 (=Gaussian distribution, bell curve)
- 正規分布 - Wikipedia
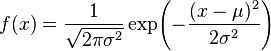
ex.
2πσ2 = 288π
σ2 = 144
σ = 12
- t-test
- two sample t-test
- t検定 - Wikipedia
- p-value
- null hypothesis
- P critical
- Reject null hypothesis
- Welch's Two-Sample t-Test

Googleの計算機使った
(0.299 - 0.307) ÷ √(0.05 ÷ 150 + 0.08 ÷ 165) = -0.27968235951 (0.05 ÷ 150 + 0.08 ÷ 165)^2 ÷ (0.05^2 ÷ (150^2 × 149) + 0.08^2 ÷ (165^2 × 164)) = 307.198799752
有効数字3桁で回答した
- Instructor Notes (Calculating t and ν)
- The answer for t given in the video is incorrect: it should be -0.280 instead of 0.280.
- The incorrect result resulted from switching the order in which the means were subtracted.
- import scipy.stats
- ttest_ind
- equal_var = False
- ttest_ind
- scipy.stats.ttest_ind — SciPy v0.14.0 Reference Guide
cohort 《統計》群、コ(ー)ホート
ネット上に模範回答が見つかった
- Segmentation fault (core dumped) になる
- udacity/Ttest.py at master · upjohnc/udacity · GitHub
- Pandas/pandas.pvalue_ttest.py at master · mirjalil/Pandas · GitHub
- df = pandas.read_csv(filename)
- df_R = df[df['handedness']=='R']
pandas.read_csv
- pandas.io.parsers.read_csv — pandas 0.15.1 documentation
- URLからも読み込める
- udacityの課題内ではだめだった
- Dropboxは
?dl=1をURLに付加
Non parametric tests
- ノンパラメトリック手法 - Wikipedia
- パラメータ(母数: 母集団を規定する量)について一切の前提を設けないもの
途中まで (1.5h)
けっこう分からないところ出てきた